
LlamaIndex喂食给AI并进化升级
将您的企业数据转化为可用于生产的LLM应用程序
LLM 提供人与数据之间的自然语言接口。LLM 预先训练过大量公开数据,但它们并非基于您的数据进行训练。您的数据可能是私有的,也可能是特定于您要解决的问题的数据。它隐藏在 AP1后面、SQL 数据库中,或隐藏在PDF 和幻灯片中。上下文增强使 LLM 可以使用您的数据来解决手头的问题。Llamalndex 提供构建任何上下文增强用例的工具,从原型到生产我们的工具允许您提取、解析、索引和处理您的数据,并快速实施将数据访问与 LLM 提示相结合的复杂查询工作流。
上下文增强最流行的示例是检索增强生成或 RAG,它在推理时将上下文与ILLM 相结合。
LlamaIndex 是一个将大语言模型(Large Language Models, LLMs,后简称大模型)和外部数据连接在一起的工具。大模型依靠上下文学习(Context Learning)来推理知识,针对一个输入(或者是prompt),根据其输出结果。因此Prompt的质量很大程度上决定了输出结果的质量,因此提示工程(Prompt engineering)现在也很受欢迎。目前大模型的输入输出长度因模型结构、显卡算力等因素影响,都有一个长度限制(以Token为单位,ChatGPT限制长度为4k个,GPT-4是32k等,Claude最新版有个100k的)。当我们外部知识的内容超过这个长度时,就无法同时将有效的信息传递给大模型。因此就诞生了 LlamaIndex 等项目。
假设有一个10w的外部数据,我们的原始输入Prompt长度为100,长度限制为4k,通过查询-检索的方式,我们能将最有效的信息提取集中在这4k的长度中,与Prompt一起送给大模型,从而让大模型得到更多的信息。此外,还能通过多轮对话的方式不断提纯外部数据,达到在有限的输入长度限制下,传达更多的信息给大模型。这部分知识可参考
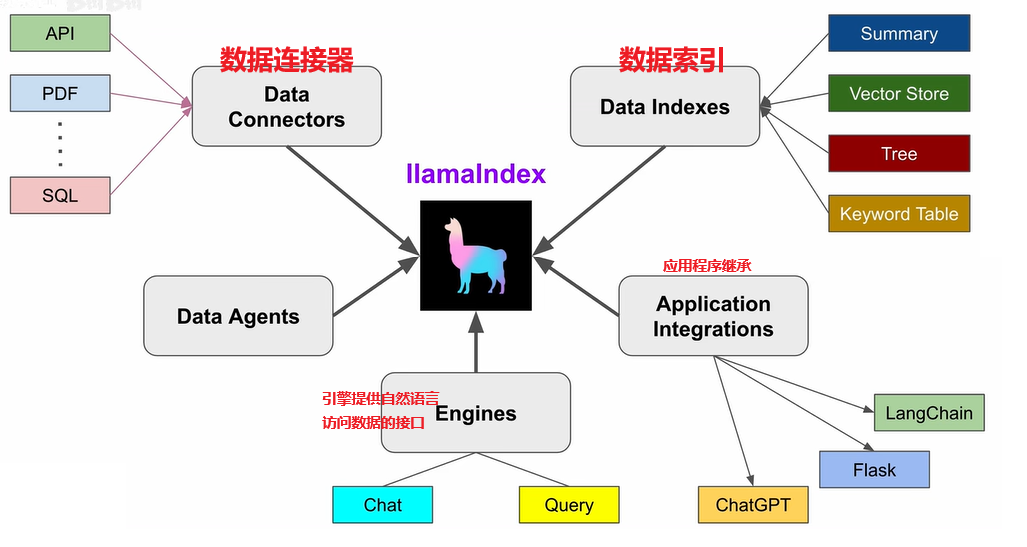
LLamaIndex的任务是通过查询、检索的方式挖掘外部数据的信息,并将其传递给大模型,因此其主要由x部分组成:
数据连接。首先将数据能读取进来,这样才能挖掘。
索引构建。要查询外部数据,就必须先构建可以查询的索引,llamdaIndex将数据存储在Node中,并基于Node构建索引。索引类型包括向量索引、列表索引、树形索引等;
查询接口。有了索引,就必须提供查询索引的接口。通过这些接口用户可以与不同的 大模型进行对话,也能自定义需要的Prompt组合方式。查询接口会完成 检索+对话的功能,即先基于索引进行检索,再将检索结果和之前的输入Prompt进行(自定义)组合形成新的扩充Prompt,对话大模型并拿到结果进行解析。
1 数据连接器(Data Connectors)
数据连接器,读取文档的工具,最简单的就是读取本地文件。 LLamaIndex 的数据连接器包括
- 本地文件、Notion、Google 文档、Slack、Discord
具体可参考Data Connectors。
2 索引结构(Index Structures)
LlamaIndex 的核心其实就是 索引结构的集合,用户可以使用索引结构或基于这些索引结构自行建图。
2.1 索引如何工作
两个概念:
- Node(节点):即一段文本(Chunk of Text),LlamaIndex读取文档(documents)对象,并将其解析/划分(parse/chunk)成 Node 节点对象,构建起索引。
- Response Synthesis(回复合成):LlamaIndex 进行检索节点并响应回复合成,不同的模式有不同的响应模式(比如向量查询、树形查询就不同),合成不同的扩充Prompt。
索引方式包括
- List Index:Node顺序存储,可用关键字过滤Node
- Vector Store Index:每个Node一个向量,查询的时候取top-k相似
- Tree Index:树形Node,从树根向叶子查询,可单边查询,或者双边查询合并。
- **Keyword Table Index**:每个Node有很多个Keywords链接,通过查Keyword能查询对应Node。
不同的索引方式决定了Query选择Node方式的不同。
回复合成方式包括:
创建并提纯(Create and Refine),即线性依次迭代;
树形总结(Tree Summarize):自底向上,两两合并,最终合并成一个回复。
3 查询接口(Query Inference)
3.1 LlamaIndex 使用模板
LlamaIndex 常用使用模版:
- 读取文档 (手动添加or通过Loader自动添加);
- 将文档解析为Nodes;
- 构建索引(从文档or从Nodes,如果从文档,则对应函数内部会完成第2步的Node解析)
- [可选,进阶] 在其他索引上构建索引,即多级索引结构
- 查询索引并对话大模型
LangChain vs LlamaIndex
要综合构建用于生产的高性能RAG程序 就用LlamaIndex
LlamaIndex官网参考:https://www.llamaindex.ai/
python文档参考:[LlamaIndex - LlamaIndex] (https://docs.llamaindex.ai/en/stable/)
LLM官网最下方的入门项目也需要学习
入门项目
RAG Work Flow
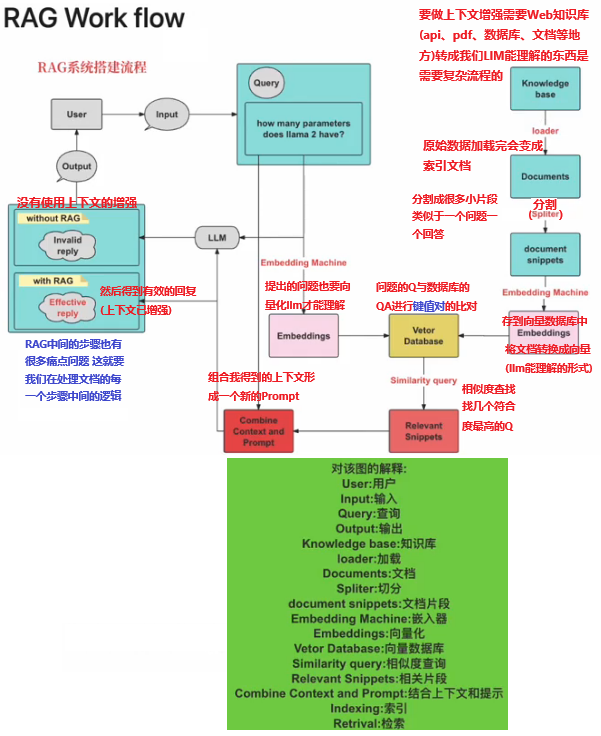
构建RAG管道—加载数据(镊取)
在您选择的 LLM 可以处理您的数据之前,您首先需要处理数据并加载数据。这与 ML 领域的数据清理/特征工程管道或传统数据设置中的 ETL 管道有相似之处。
此引入管道通常包括三个主要阶段:
- 加载数据
- 转换数据
- 索引和存储数据
我们将在后面的章节中介绍索引 / 存储。在本指南中,我们将主要讨论 loader 和 transformations。
装载机
在您选择的 LLM 可以处理您的数据之前,您需要加载它。LlamaIndex 执行此作的方式是通过数据连接器(也称为 .Data Connector 从不同的数据源摄取数据并将数据格式化为对象。A 是有关该数据的数据(当前为文本,将来为图像和音频)和元数据的集合。Reader Document Document
使用 SimpleDirectoryReader 加载
最容易使用的阅读器是我们的 SimpleDirectoryReader,它从给定目录中的每个文件创建文档。它内置于 LlamaIndex 中,可以读取多种格式,包括 Markdown、PDF、Word 文档、PowerPoint 幻灯片、图像、音频和视频。
from llama_index.core import SimpleDirectoryReader
documents = SimpleDirectoryReader("./data").load_data()
★ ★ ★ ★ 更多教程请看官方接口文档 Loading Data (Ingestion) - LlamaIndex ★ ★ ★ ★
Starter Tutorial - LlamaIndex + 欢迎使用 Colaboratory - Colab = 在线使用代码

RAG
RAG,也称为检索增强生成,是利用个人或私域数据增强 LLM 的一种范式。通常,它包含两个阶段:
索引
构建知识库。
查询
从知识库检索相关上下文信息,以辅助
LLM回答问题。
LlamaIndex 提供了工具包帮助开发者极其便捷地完成这两个阶段的工作。
索引阶段
LlamaIndex 通过提供 Data connectors(数据连接器) 和 Indexes (索引) 帮助开发者构建知识库。
该阶段会用到如下工具或组件:
Data connectors
数据连接器。它负责将来自不同数据源的不同格式的数据注入,并转换为
LlamaIndex支持的文档(Document)表现形式,其中包含了文本和元数据。Documents / Nodes
Document是
LlamaIndex中容器的概念,它可以包含任何数据源,包括,PDF文档,API响应,或来自数据库的数据。Node是
LlamaIndex中数据的最小单元,代表了一个 Document的分块。它还包含了元数据,以及与其他Node的关系信息。这使得更精确的检索操作成为可能。Data Indexes
LlamaIndex提供便利的工具,帮助开发者为注入的数据建立索引,使得未来的检索简单而高效。最常用的索引是向量存储索引 -
VectorStoreIndex。
查询阶段
在查询阶段,RAG 管道根据的用户查询,检索最相关的上下文,并将其与查询一起,传递给 LLM,以合成响应。这使 LLM 能够获得不在其原始训练数据中的最新知识,同时也减少了虚构内容。该阶段的关键挑战在于检索、编排和基于知识库的推理。
LlamaIndex 提供可组合的模块,帮助开发者构建和集成 RAG 管道,用于问答、聊天机器人或作为代理的一部分。这些构建块可以根据排名偏好进行定制,并组合起来,以结构化的方式基于多个知识库进行推理。
该阶段的构建块包括:
Retrievers
检索器。它定义如何高效地从知识库,基于查询,检索相关上下文信息。
Node Postprocessors
Node后处理器。它对一系列文档节点(Node)实施转换,过滤,或排名。
Response Synthesizers
响应合成器。它基于用户的查询,和一组检索到的文本块(形成上下文),利用
LLM生成响应。
RAG管道包括:
Query Engines
查询引擎 - 端到端的管道,允许用户基于知识库,以自然语言提问,并获得回答,以及相关的上下文。
Chat Engines
聊天引擎 - 端到端的管道,允许用户基于知识库进行对话(多次交互,会话历史)。
Agents
代理。它是一种由
LLM驱动的自动化决策器。代理可以像查询引擎或聊天引擎一样使用。主要区别在于,代理动态地决定最佳的动作序列,而不是遵循预定的逻辑。这为其提供了处理更复杂任务的额外灵活性。
LlamaIndex个性化配置
LlamaIndex 对 RAG 过程提供了全面的配置支持,允许开发者对整个过程进行个性化设置。常见的配置场景包括:
- 自定义文档分块
- 自定义向量存储
- 自定义检索
- 指定
LLM - 指定响应模式
- 指定流式响应
注,个性化配置主要通过 LlamaIndex 提供的 ServiceContext 类实现。
配置场景示例
接下来通过简明示例代码段展示 LlamaIndex 对各种配置场景的支持。
自定义文档分块
from llama_index import ServiceContext
service_context = ServiceContext.from_defaults(chunk_size=500)
自定义向量存储
import chromadb
from llama_index.vector_stores import ChromaVectorStore
from llama_index import StorageContext
chroma_client = chromadb.PersistentClient()
chroma_collection = chroma_client.create_collection("quickstart")
# 向量存储
vector_store = ChromaVectorStore(chroma_collection=chroma_collection)
storage_context = StorageContext.from_defaults(vector_store=vector_store)
自定义检索
自定义检索中,我们可以通过参数指定查询引擎(Query Engine)在检索时请求的相似文档数。
index = VectorStoreIndex.from_documents(documents)
query_engine = index.as_query_engine(similarity_top_k=5)
指定 LLM
# 指定大语言模型
service_context = ServiceContext.from_defaults(llm=OpenAI())
指定响应模式
query_engine = index.as_query_engine(response_mode='tree_summarize')
指定流式响应
# 流式响应
query_engine = index.as_query_engine(streaming=True)
完整实例
GitHub:LlamaIndex-Tutorials/03_Customization/03_Customization.ipynb at main · sugarforever/LlamaIndex-Tutorials
Colab:03_Customization.ipynb - Colab
请参考03_Customization.ipynb ,这是一个基于第1课的示例实现上述的所有个性化配置:
- 文档分块大小:500
- Chromadb作为向量存储
- 自定义检索文档数为5
- 指定大模型为OpenAI的模型
- 响应模式为
tree_summarize - 问答实现流式响应
注,响应模式会在后续课程中详细介绍。
强大的数据连接器
开源教程:LlamaIndex-Tutorials/04_Data_Connectors at main · sugarforever/LlamaIndex-Tutorials
演示实例:04_Data_Connectors.ipynb - Colab
文档与节点
开源教程:LlamaIndex-Tutorials/05_Documents_Nodes at main · sugarforever/LlamaIndex-Tutorials